toiota
-
Innlegg
38 -
Ble med
-
Besøkte siden sist
Innholdstype
Profiler
Forum
Hendelser
Blogger
Om forumet
Alt skrevet av toiota
-
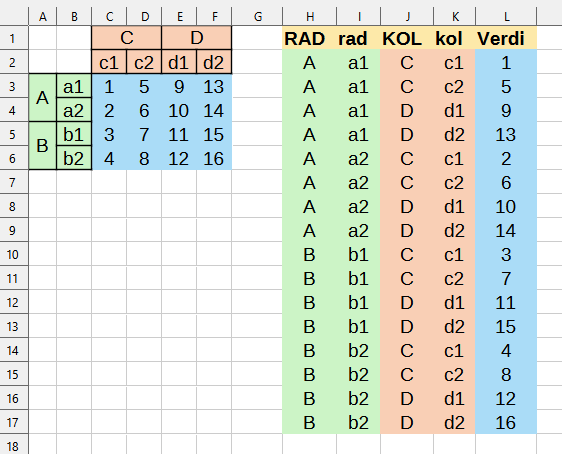
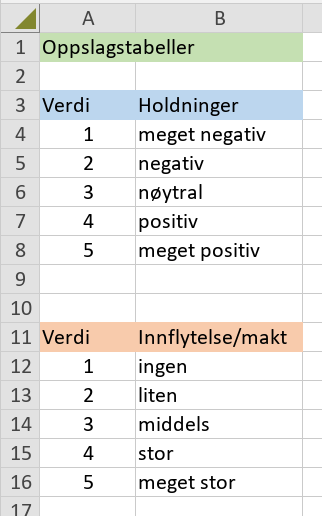
Nytt løsningsforslag, som også denne gang ikke er i Excel, men det nærmer seg ... :-) - Programvare: Calc, LibreOffice_24.2.1_Win_x86-64.msi - LibreOffice Extension: Decroise v.1.8.5 (fra 2009/2010 !!!) Lastet den ned fra LibreOffice Calc: Tools > Extensions... > lenken "Get more extensions online..." > Søk: decroise Resultattabellen mangler kolonneoverskrifter, så de må legges inn manuelt (gulorange bakgrunnfarge) Kolonne "Verdi" i resultattabellen kan nå filtreres, eller du kan laste resultattabellen inn i en database, og jobbe videre med den der. Den følgende skjermdumpen viser at "decroise" også håndterer doble rad- og kolonnenavn.

-
 Butikk: https://www.fanatical.com/ Dollar Collections. Bundles & Packs from $1. https://www.fanatical.com/en/collections/dollar-collections/ Alle spillene er Steam-spill Totalsum for alle spillene: kr 110 (Steam Store prisene er fra 24. mars) Donut County (ROW), kr 35.86 (Steam kr 135) Double Pack: kr 20.91 - Styx: Master of Shadows - Styx: Shards of Darkness Steam Store: STYX COLLECTION, kr 388.08, -5% Classic Comnplete'n'Tasty Pack: kr 11.68 - Oddworld: Abe's Exoddus RETAIL (Steam kr 20) [*] - Oddworld: Abes Oddysee RETAIL (Steam kr 20) [*] - Oddworld: Munch's Oddysee RETAIL (Steam kr 36) [*] - Oddworld: New 'n' Tasty (Steam kr 140) - Oddworld: New 'n' Tasty - Alf's Escape (Steam kr 20) - Oddworld: New 'n' Tasty - Scrub Abe (Steam kr 7) - Oddworld: Stranger's Wrath RETAIL (Steam kr 70) [*] [*]: Steam Store: THE ODDBOXX, kr 86, -41% Learn Japanese Trilogy: kr 11.68 - Learn Japanese To Survive! Hiragana Battle - Learn Japanese To Survive! Kanji Combat - Learn Japanese To Survive! Katakana War Steam Store: Japanese To Survive! Trilogy BUNDLE, kr 145.80, -10% Giana Sisters: Twisted Bundle: kr 11.68 - Giana Sisters: Twisted Dreams - Giana Sisters: Twisted Dreams - Rise of the Owlverlord Steam Store: GIANA SISTERS: TWISTED BUNDLE, kr 126, -7% Double Pack: kr 17.40 - Call of Juarez - Call of Juarez: Bound in Blood Steam Store: CALL OF JUAREZ BUNDLE, kr 282.60, -10% Takk for tipset vidor! Jeg var ikke klar over denne nettbutikken. Kilde: https://www.diskusjon.no/topic/1629519-gratis-spill-og-bra-tilbud-tråd/page/36/#
Butikk: https://www.fanatical.com/ Dollar Collections. Bundles & Packs from $1. https://www.fanatical.com/en/collections/dollar-collections/ Alle spillene er Steam-spill Totalsum for alle spillene: kr 110 (Steam Store prisene er fra 24. mars) Donut County (ROW), kr 35.86 (Steam kr 135) Double Pack: kr 20.91 - Styx: Master of Shadows - Styx: Shards of Darkness Steam Store: STYX COLLECTION, kr 388.08, -5% Classic Comnplete'n'Tasty Pack: kr 11.68 - Oddworld: Abe's Exoddus RETAIL (Steam kr 20) [*] - Oddworld: Abes Oddysee RETAIL (Steam kr 20) [*] - Oddworld: Munch's Oddysee RETAIL (Steam kr 36) [*] - Oddworld: New 'n' Tasty (Steam kr 140) - Oddworld: New 'n' Tasty - Alf's Escape (Steam kr 20) - Oddworld: New 'n' Tasty - Scrub Abe (Steam kr 7) - Oddworld: Stranger's Wrath RETAIL (Steam kr 70) [*] [*]: Steam Store: THE ODDBOXX, kr 86, -41% Learn Japanese Trilogy: kr 11.68 - Learn Japanese To Survive! Hiragana Battle - Learn Japanese To Survive! Kanji Combat - Learn Japanese To Survive! Katakana War Steam Store: Japanese To Survive! Trilogy BUNDLE, kr 145.80, -10% Giana Sisters: Twisted Bundle: kr 11.68 - Giana Sisters: Twisted Dreams - Giana Sisters: Twisted Dreams - Rise of the Owlverlord Steam Store: GIANA SISTERS: TWISTED BUNDLE, kr 126, -7% Double Pack: kr 17.40 - Call of Juarez - Call of Juarez: Bound in Blood Steam Store: CALL OF JUAREZ BUNDLE, kr 282.60, -10% Takk for tipset vidor! Jeg var ikke klar over denne nettbutikken. Kilde: https://www.diskusjon.no/topic/1629519-gratis-spill-og-bra-tilbud-tråd/page/36/# -
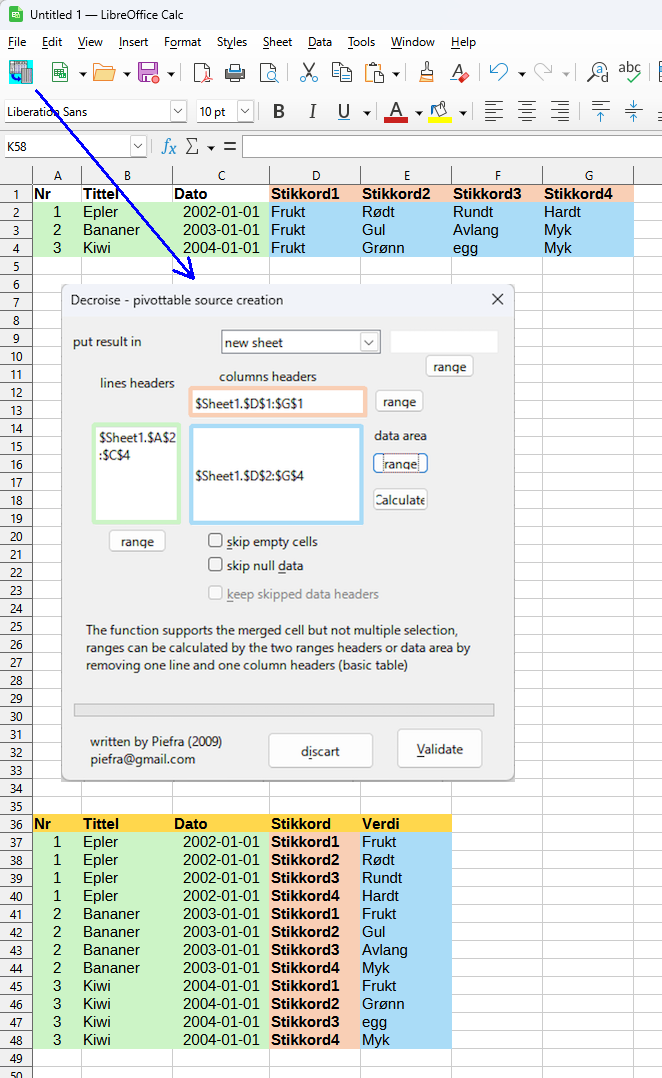
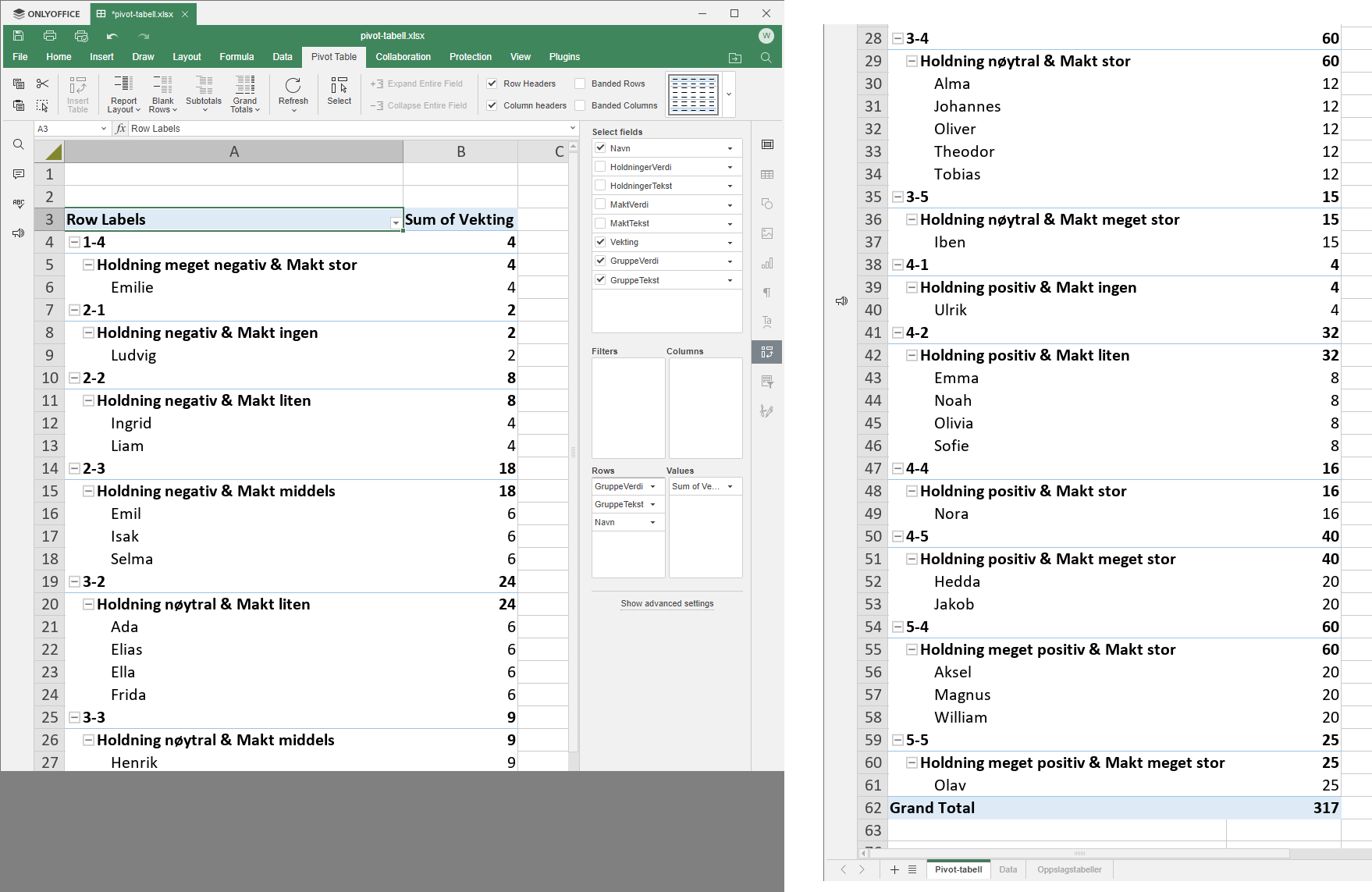
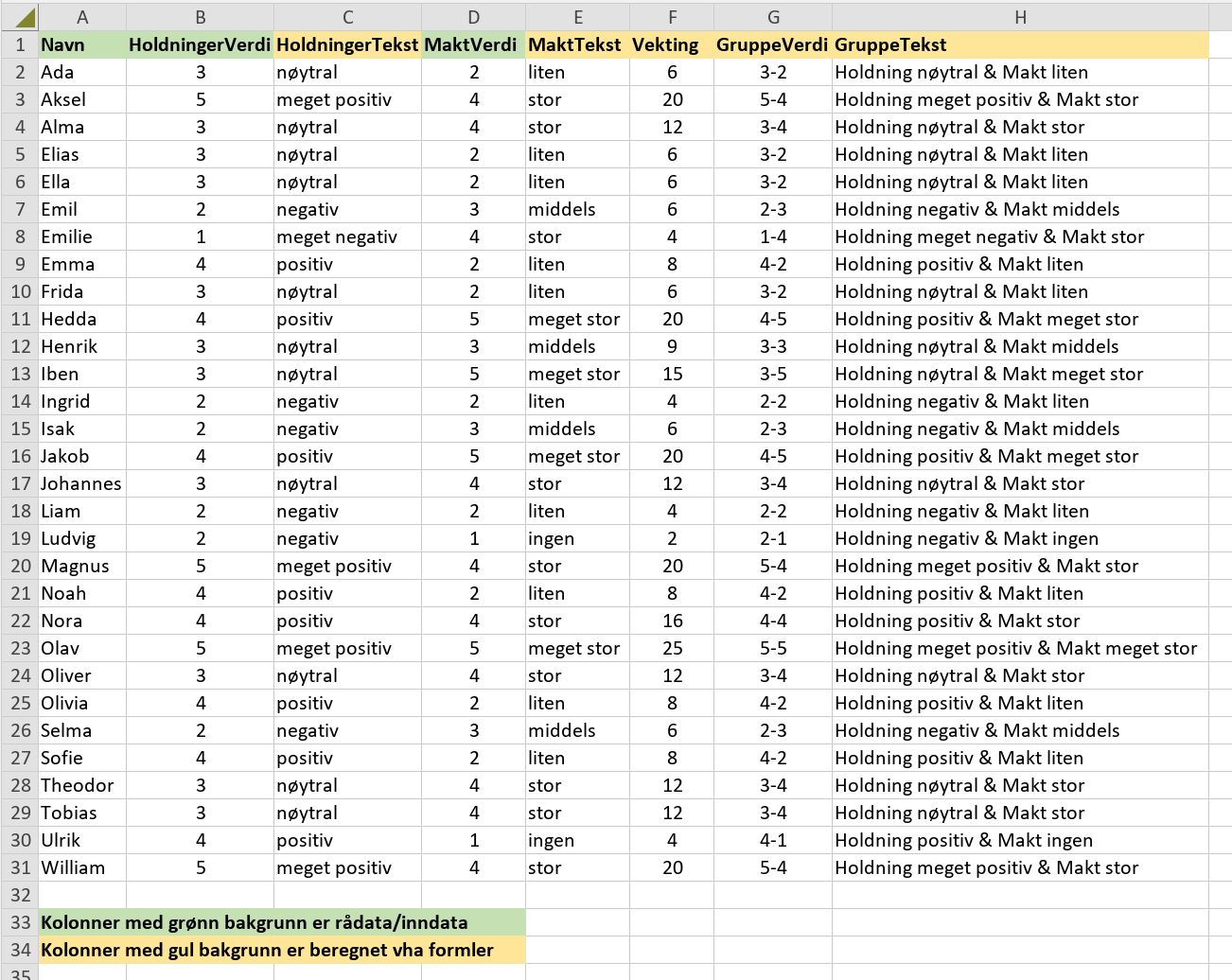
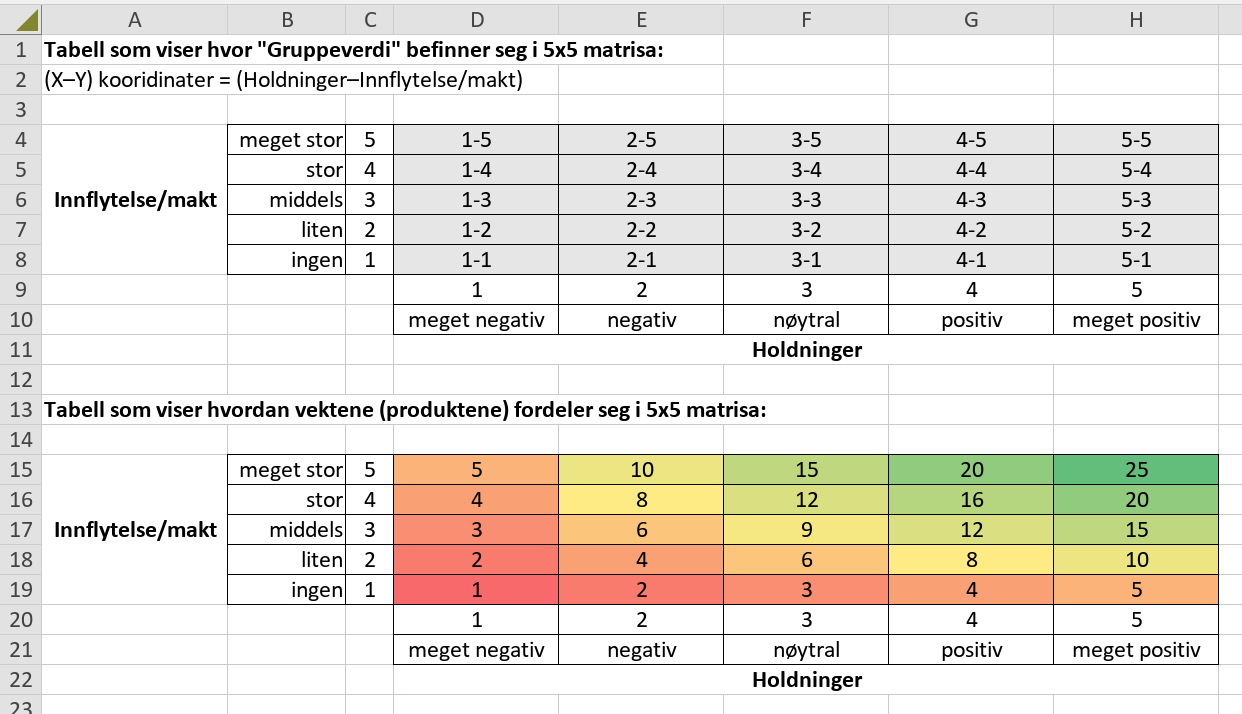
Det nærmeste jeg kommer en løsning er en Pivot-tabell som viser informasjonen du er ute etter, men ikke i en 5x5 matrise. Programvare: "Spreadsheet" i office-pakken: ONLYOFFICE Desktop Editors for Windows, v8.0.1 nor.jorgen, takk for at du nevnte vlookup-funksjonen, den fikk jeg sannelig bruk for. Drop down liste skal sjekkes ut senere :-) Regneark: "pivot-tabell-v2.xlsx" Ark: Data Kolonne C: =VLOOKUP(B2,Oppslagstabeller!$A$4:B34,2,FALSE) Kolonne E: =VLOOKUP(D2,Oppslagstabeller!$A$12:B42,2,FALSE) Kolonne F =B2*D2 Kolonne G =CONCAT(B2,"-",D2) Kolonne H =CONCAT("Holdning ",C2," & Makt ",E2) pivot-tabell-v2.xlsx
-
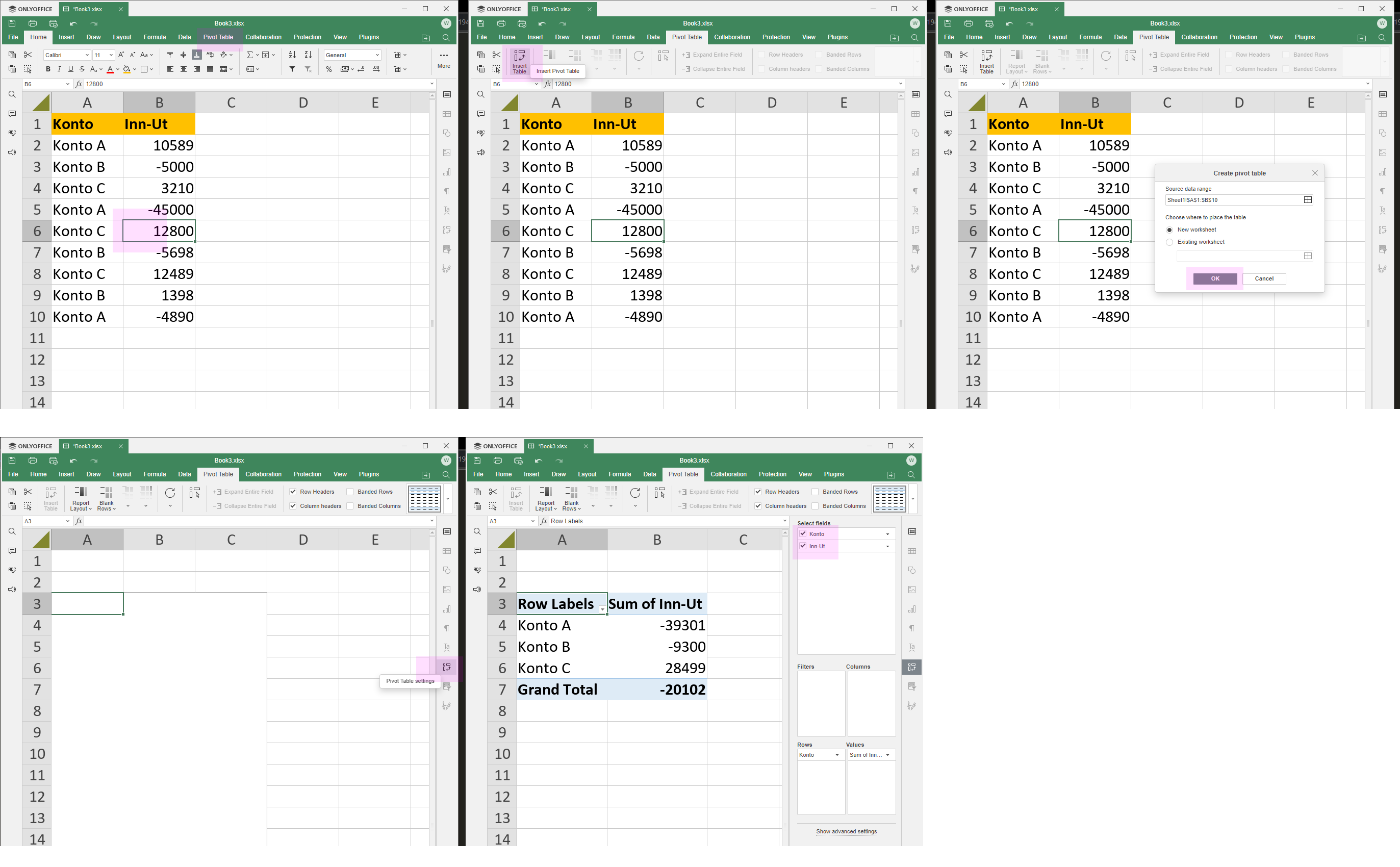
Jeg er nybegynner angående Pivot-tabeller, men ser at dette er et veldig nyttig verktøy å ha i verktøykassa. Løsningsforlaget er ikke gjort i Excel, men i Spreadsheet fra ONLYOFFICE Desktop Editors v.8.0.1 Etter å ha åpnet Excel-fila, tok det bare 7 klikk (se vedlagt skjermdump) før jeg fikk resultatet ved hjelp av en Pivot-tabell. Pivot-tabeller kan absolutt gjøre vei i vellinga! :-)
-
Excel: Vise hvilke linjer ting ligger på i ett regne ark
toiota svarte på AndersT2 sitt emne i Programvare
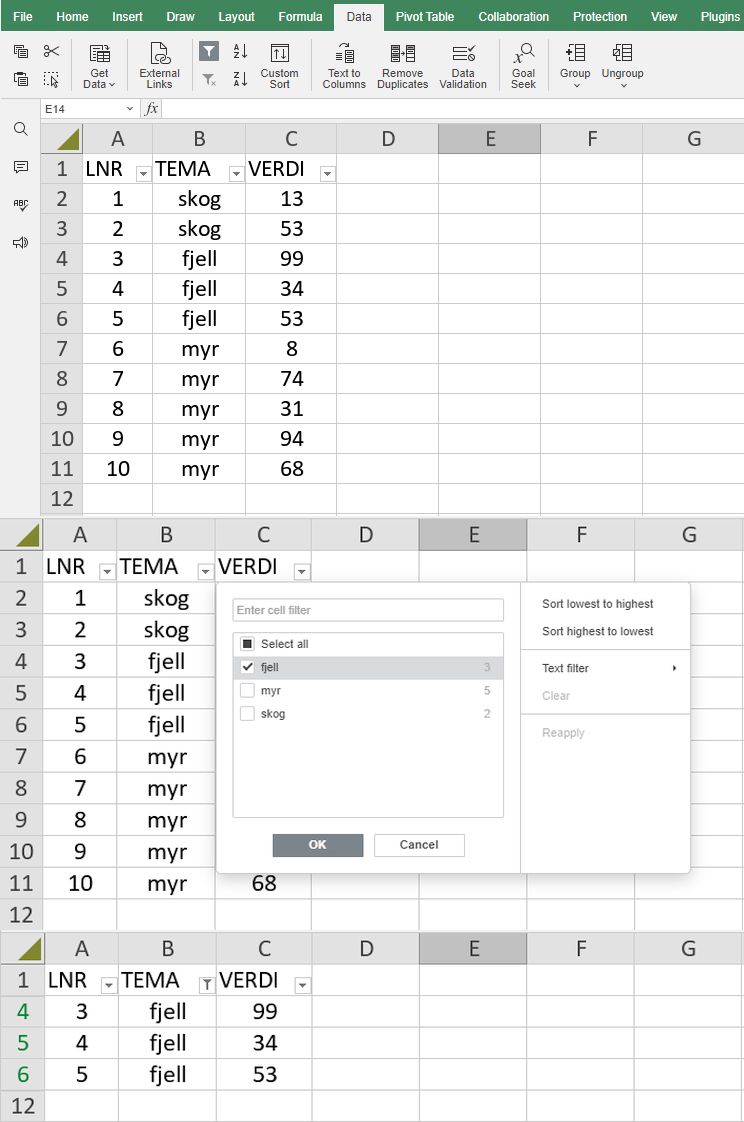
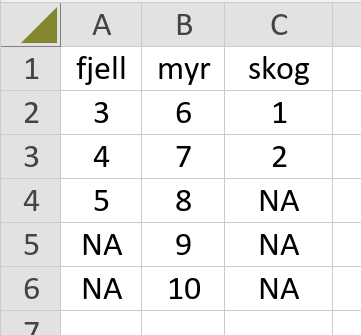
NoBo har helt rett! Hvorfor gjøre det lett når man kan gjøre det vanskelig. Jeg har visst gravd meg litt for dypt ned "R-hullet" :-) Her kommer et løsningsforslag for regneark: Jeg la til en kolonne med linjenummer i regnearket. Etter filtrering av f. eks. temaet "fjell", kan du kopiere ut linjenumrene som innholder temaet "fjell".
-
Excel: Vise hvilke linjer ting ligger på i ett regne ark
toiota svarte på AndersT2 sitt emne i Programvare
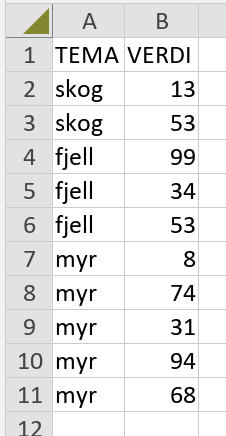
Her har du mitt løsningsforslag i R. Husk å forandre `setwd(...)` til mappen som inneholder Excel fila. Fil: `my_script.R` # R version 4.3.3 (2024-02-29 ucrt) -- "Angel Food Cake" # 0. Sjekker om "tidyverse" allerede er installert. check_and_install <- function(package){ if (!package %in% rownames(installed.packages())){ install.packages(package) } } check_and_install("tidyverse") #install.packages("tidyverse") library(tidyverse) # v2.0.0 library(readxl) # v1.4.3 # 1. Last inn excel-fila setwd("C:/my-project/Excel-Vise-hvilke-linjer-ting-ligger-pa-i-ett-regne-ark") tema <- readxl::read_xlsx("tema.xlsx") # Vis datasett tema #> # A tibble: 10 × 2 #> TEMA VERDI #> <chr> <dbl> #> 1 skog 13 #> 2 skog 53 #> 3 fjell 99 #> 4 fjell 34 #> 5 fjell 53 #> 6 myr 8 #> 7 myr 74 #> 8 myr 31 #> 9 myr 94 #> 10 myr 68 # 2. Gruppér datasettet etter TEMA by_tema <- tema %>% dplyr::group_by(TEMA) # Vis gruppert datasett by_tema #> # A tibble: 10 × 2 #> # Groups: TEMA [3] #> TEMA VERDI #> <chr> <dbl> #> 1 skog 13 #> 2 skog 53 #> 3 fjell 99 #> 4 fjell 34 #> 5 fjell 53 #> 6 myr 8 #> 7 myr 74 #> 8 myr 31 #> 9 myr 94 #> 10 myr 68 # 3. Vis grupper # (NB! Gruppene er sortert alfabetisk, og gitt en indeks) by_tema %>% group_keys() #> # A tibble: 3 × 1 #> TEMA #> <chr> #> 1 fjell #> 2 myr #> 3 skog # 4. Lagre temanavn til senere bruk temanavn <- by_tema %>% group_keys() %>% unlist(use.names = FALSE) temanavn #> [1] "fjell" "myr" "skog" # 5. Vis antall rader i hver gruppe by_tema %>% tally() #> # A tibble: 3 × 2 #> TEMA n #> <chr> <int> #> 1 fjell 3 #> 2 myr 5 #> 3 skog 2 # 6. Vis hvilken gruppeindeks hver rad tilhører # Info: 1=fjell, 2=myr, 3=skog by_tema %>% group_indices() #> [1] 3 3 1 1 1 2 2 2 2 2 # 7. Vis hvilken gruppe hver rad tilhører # (dette burde være noe for deg!) radnummer <- by_tema %>% group_rows() names(radnummer) <- temanavn radnummer #> <list_of<integer>[3]> #> $fjell #> [1] 3 4 5 #> #> $myr #> [1] 6 7 8 9 10 #> #> $skog #> [1] 1 2 # 8. Lag tabell df <- as_tibble(lapply(radnummer, `length<-`, max(lengths(radnummer)))) df #> # A tibble: 5 × 3 #> fjell myr skog #> <int> <int> <int> #> 1 3 6 1 #> 2 4 7 2 #> 3 5 8 NA #> 4 NA 9 NA #> 5 NA 10 NA # 9. Lagre tabellen som en CSV-fil som kan åpnes i Excel. readr::write_excel_csv(df, "tema_radnummer.csv") Fil: `my_script_minimal.R` Inneholder ingen kommentarer og output. # R version 4.3.3 (2024-02-29 ucrt) -- "Angel Food Cake" check_and_install <- function(package){ if (!package %in% rownames(installed.packages())){ install.packages(package) } } check_and_install("tidyverse") library(tidyverse) # v2.0.0 library(readxl) # v1.4.3 setwd("C:/my-project/Excel-Vise-hvilke-linjer-ting-ligger-pa-i-ett-regne-ark") tema <- readxl::read_xlsx("tema.xlsx") by_tema <- tema %>% dplyr::group_by(TEMA) temanavn <- by_tema %>% group_keys() %>% unlist(use.names = FALSE) radnummer <- by_tema %>% group_rows() names(radnummer) <- temanavn df <- as_tibble(lapply(radnummer, `length<-`, max(lengths(radnummer)))) readr::write_excel_csv(df, "tema_radnummer.csv") my_script.R my_script_minimal.R tema.csv tema.xlsx tema_radnummer.csv
- 7 svar
-
- 1
-

-
Her har du et løsningsforslag i R: The R Project for Statistical Computing, der jeg bruker funksjonene `group_by()`, `summarise()` og sum(). Jeg brukte dine data, bortsett fra at jeg endret kolonnenavnet "Beløp" til "Belop". Spør dersom det er noe du lurer på. `my_script.R`: install.packages("tidyverse") library(tidyverse) # NB! Linjer som begynner med `#> ` er OUTPUT. setwd("C:/my-project/Excel-Hvordan-betinget-summere-tall-i-en-tabell") getwd() # sjekker at "working directory" er korrekt. # Jeg lagret dine data i en CSV-fil `konto-belop.csv` # (Du kan eksportere Excel-fila di som ei CSV-fil) # Laster inn CSV-fila: KontoBelop <- readr::read_csv(file="konto-belop.csv") KontoBelop # Se på data #> # A tibble: 9 × 2 #> Konto Belop #> <chr> <dbl> #> 1 Konto A 10589 #> 2 Konto B -5000 #> 3 Konto C 3210 #> 4 Konto A -45000 #> 5 Konto C 12800 #> 6 Konto B -5698 #> 7 Konto C 12489 #> 8 Konto B 1398 #> 9 Konto A -4890 # Grupper data etter Konto by_Konto <- KontoBelop %>% dplyr::group_by(Konto) by_Konto # Se på gruppert data #> # A tibble: 9 × 2 #> # Groups: Konto [3] #> Konto Belop #> <chr> <dbl> #> 1 Konto A 10589 #> 2 Konto B -5000 #> 3 Konto C 3210 #> 4 Konto A -45000 #> 5 Konto C 12800 #> 6 Konto B -5698 #> 7 Konto C 12489 #> 8 Konto B 1398 #> 9 Konto A -4890 # Vis antall rader i hver gruppe og sum for hver gruppe by_Konto %>% dplyr::summarise( AntallRader = n(), Sum = sum(Belop, na.rm = TRUE) # `na.rm = TRUE` sletter alle tomme rader ) #> # A tibble: 3 × 3 #> Konto AntallRader Sum #> <chr> <int> <dbl> #> 1 Konto A 3 -39301 #> 2 Konto B 3 -9300 #> 3 Konto C 3 28499 # Beregn kun sum for hver gruppe sum_by_Konto <- by_Konto %>% summarise( Sum = sum(Belop, na.rm = TRUE), ) sum_by_Konto #> # A tibble: 3 × 2 #> Konto Sum #> <chr> <dbl> #> 1 Konto A -39301 #> 2 Konto B -9300 #> 3 Konto C 28499 # Lagre resultatet som en CSV-fil som deretter kan åpnes i Excel: readr::write_excel_csv(sum_by_Konto, "sum_by_konto.csv") konto-belop.csv my_script.R sum_by_konto.csv
-
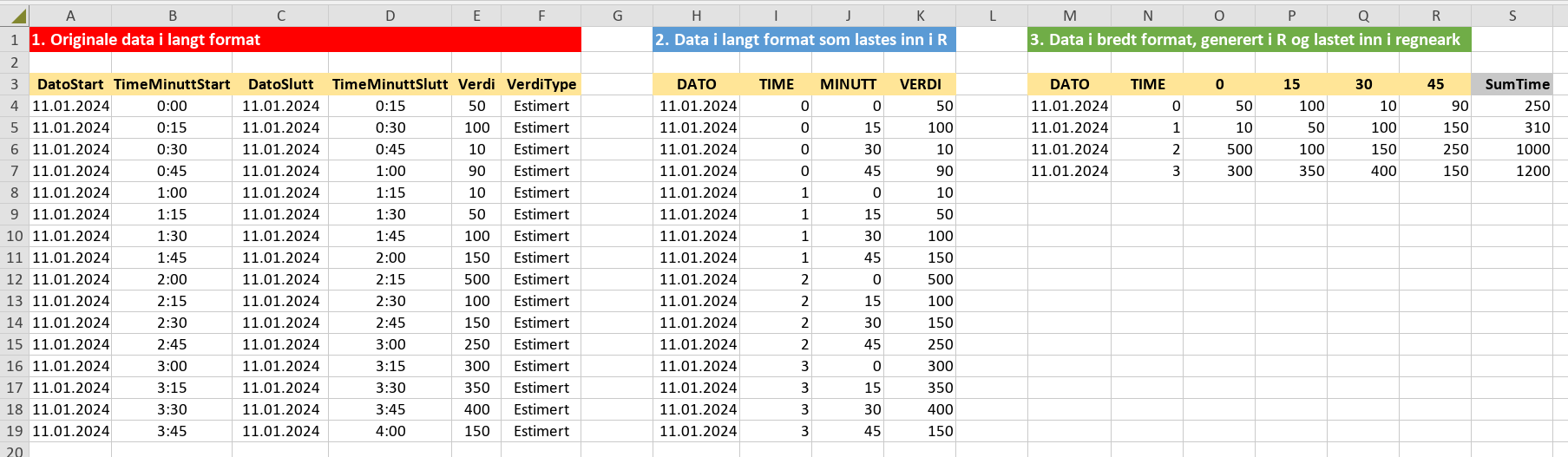
Hei iuet, En løsning er å omforme datasettet ditt fra langt format til bredt format. Det gjør det mye enklere å regne ut timesummen i regnearket. Jeg kan ikke pivot-tabeller, så jeg har implementert en løsning i R. R kan lastes ned her: https://www.r-project.org/ RStudio IDE/RStudio Desktop (Open Source Edition) er en gratis men det er ikke nødvendig for mitt løsningsforslag. (27. des. 2023 postet jeg et tilsvarende løsningsforslag her) Spør om det noe i koden du lurer på! # #### START R KILDEKODEN ############ # NOTE: R kildekoden kan lagres i en R skriptfil, f.eks. `my_script.R`. # Åpne skiptet i R og kjør hele skriptet på en gang eller kjør linje for linje. # Programvare: R version 4.3.3 (2024-02-29 ucrt) -- "Angel Food Cake" install.packages("tidyverse") library(tidyverse) # Jeg har tatt utgangspunkt i ditt datasett med 6 kolonner: # DatoStart | TimeMinuttStart | DatoSlutt | TimeMinuttSlutt | Verdi | VerdiType # ----------------------------------------------------------------------------- # 11.01.2024 00:00 11.01.2024 00:15 50 Estimert # 11.01.2024 00:15 11.01.2024 00:30 100 Estimert # 11.01.2024 00:30 11.01.2024 00:45 10 Estimert # 11.01.2024 00:45 11.01.2024 01:00 90 Estimert # 11.01.2024 01:00 11.01.2024 01:15 10 Estimert # 11.01.2024 01:15 11.01.2024 01:30 50 Estimert # 11.01.2024 01:30 11.01.2024 01:45 100 Estimert # 11.01.2024 01:45 11.01.2024 02:00 150 Estimert # 11.01.2024 02:00 11.01.2024 02:15 500 Estimert # 11.01.2024 02:15 11.01.2024 02:30 100 Estimert # 11.01.2024 02:30 11.01.2024 02:45 150 Estimert # 11.01.2024 02:45 11.01.2024 03:00 250 Estimert # 11.01.2024 03:00 11.01.2024 03:15 300 Estimert # 11.01.2024 03:15 11.01.2024 03:30 350 Estimert # 11.01.2024 03:30 11.01.2024 03:45 400 Estimert # 11.01.2024 03:45 11.01.2024 04:00 150 Estimert # Jeg har forenklet ditt eksempel ved å slette kolonnene: "DatoSlutt", "TimeMinuttSlutt", # "VerdiType". # Din kolonne "TimeMinuttStart" har jeg delt opp i to nye kolonner: "TIME" og "MINUTT". # Opprett ei csv-fil med følgende data, ikke ta med `# ` i starten av linjene: # Gi fila navnet "data-long.csv", så lagrer du den i "C:/temp/". # DATO,TIME,MINUTT,VERDI # "11.01.2024",0,0,50 # "11.01.2024",0,15,100 # "11.01.2024",0,30,10 # "11.01.2024",0,45,90 # "11.01.2024",1,0,10 # "11.01.2024",1,15,50 # "11.01.2024",1,30,100 # "11.01.2024",1,45,150 # "11.01.2024",2,0,500 # "11.01.2024",2,15,100 # "11.01.2024",2,30,150 # "11.01.2024",2,45,250 # "11.01.2024",3,0,300 # "11.01.2024",3,15,350 # "11.01.2024",3,30,400 # "11.01.2024",3,45,150 setwd("C:/temp") # arbeidsmappe hvor csv-fila er. getwd() # sjekk sti # Åpne datafila data_long <- readr::read_csv(file="data_long.csv") data_long #> # A tibble: 16 × 4 #> DATO TIME MINUTT VERDI #> <chr> <dbl> <dbl> <dbl> #> 1 11.01.2024 0 0 50 #> 2 11.01.2024 0 15 100 #> 3 11.01.2024 0 30 10 #> 4 11.01.2024 0 45 90 #> 5 11.01.2024 1 0 10 #> 6 11.01.2024 1 15 50 #> 7 11.01.2024 1 30 100 #> 8 11.01.2024 1 45 150 #> 9 11.01.2024 2 0 500 #> 10 11.01.2024 2 15 100 #> 11 11.01.2024 2 30 150 #> 12 11.01.2024 2 45 250 #> 13 11.01.2024 3 0 300 #> 14 11.01.2024 3 15 350 #> 15 11.01.2024 3 30 400 #> 16 11.01.2024 3 45 150 # Så omformer datasettet til bredt format, dette formatet gjør det enklere # å beregne timesummen når du senere åpner csv-fila i regnearket. data_wide <- data_long |> tidyr::pivot_wider( names_from = "MINUTT", values_from = "VERDI" ) data_wide #> # A tibble: 4 × 6 #> DATO TIME `0` `15` `30` `45` #> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> #> 1 11.01.2024 0 50 100 10 90 #> 2 11.01.2024 1 10 50 100 150 #> 3 11.01.2024 2 500 100 150 250 #> 4 11.01.2024 3 300 350 400 150 # Lagre `data_wide` som en csv-fil, som kan åpnes i regnearket. # NB! Fjern `# ` i neste linje for å kunne lagre filen. # readr::write_excel_csv(data_wide, "data_wide.csv") # Nå kan du åpne `data_wide.csv` i regnearket å beregne timesummen. # #### SLUTT PÅ MITT LØSNINGSFORSLAG ############ # Litt ekstra info: # For å gå fra bredt format til langt format bruker du funksjonen `pivot_longer()`: new_long <- data_wide |> tidyr::pivot_longer( cols = c(`0`, `15`, `30`, `45`), names_to = "MINUTT", values_to = "VERDI" ) new_long # NB! Fjern `# ` i neste linje for å kunne lagre filen. # readr::write_excel_csv(new_long, "new_long_data.csv") # #### SLUTT R KILDEKODE ######## new_long_data.csv data_wide.csv my_script.R data_long.csv
-
Hei *Magnus*, jeg har samme laptop som deg, men med 4060. (kjøpt feb. 2024) -- "Kingston FURY Impact DDR5 5600MHz 32GB - Minnebrikker - Komplett.no" er kompatibelt -- har kjøpt samme minne. -- "Kingston FURY 2TB - SSD M.2 - Komplett.no" er jeg litt usikker på. Denne M.2'en er tosidig, og dermed litt tykkere enn den som følger med laptop'en (Samsung 512GB, ensidig). Jeg tok ingen sjanser og kjøpte en ensidig M.2 SSD. Generelt avgir ensidige mindre varme og er mer strømgjerrige. Forslag til ensidige: Western Digital SN850X 2 TB Samsung 980 Pro 2 TB Samsung 990 Pro 2 TB Lexar NM790 2 TB Crucial P3 Plus 2 TB Kilde: TechPowerUp: SSD Specs Database
-
Hei, jeg anbefaler alle å prøve disse vanvittig gode danske "knaskemandlene"! https://www.valdemarsro.dk/braendte-mandler/
-
Dette programmet tror jeg kan spare deg mye tid: WinSetView Globally Set Explorer Folder Views (siste versjon 2.92 ble lastet opp 9. mars 2024) https://github.com/LesFerch/WinSetView/ Tips! Les litt i manualen før/dersom du velger å bruke programmet. Lykke til !
-
Hei Tangent, Se om dette funker: 1. Start "File Explorer" i Windows 11 1.1. Gå til en mappe med musikkfiler. (f.eks. ....\Bob Dylan\19660516 - Blond on Blond\) 1.2. Klikk [View] > Details 1.3. Klikk [...] > Options 2. Folder Option: Klikk [View]-tab 2.1. Folder views: Klikk [Apply to Folders]